第二章 k8s 基本概念
1. Kubernetes API
对于k8s进行操作,需要借助于Kubernetes API,对于集群的预期状态进行描述。k8s提供了声明式的对象描述方式,用户只需要声明所需要的集群状态,不需要考虑如何达到该状态。这些状态包括:运行的应用、负载、使用的镜像、副本数、所需要的网络以及存储资源等。可以使用 kubectl 命令行工具调用 Kubernetes API,也可以借助于客户端库和集群进行交互。一旦,设置了预期状态,k8s的控制面板(control plane)会通过 Pod 生命周期事件生成器(PLEG), 执行各类任务(创建或者重启pod,调整副本数等),达到所需要的状态。
control plane 由一组集群上的进程组成:
Master: 运行在Master节点上的主控组件,包括: kube-apiserver, kube-controller-manager, kube-scheduler
Node: 运行在非master节点的组件,包含两个进程:kubelet(与master通信), kube-proxy(将k8s网络服务代理到每一个节点)
1.1 管理方式
命令行式命令: 直接使用命令行
命令式对象配置: 声明单个对象的配置文件
声明式对象配置: 声明多个对象的配置文件
2. Kubernetes abstractions
k8s 使用多级抽象表示系统状态,其中包括了底层抽象以及大量的被称为控制器 (Controller) 的高级抽象,其中基本的k8s对象包括:
Pod
Service
Volume
Namespace
高级抽象 (Controller):
ReplicaSet
Deployment
StatefulSet
DaemonSet
Job
2.1 k8s 6 层抽象
对于一个无状态且持续运行的应用,可以进行以下抽象:
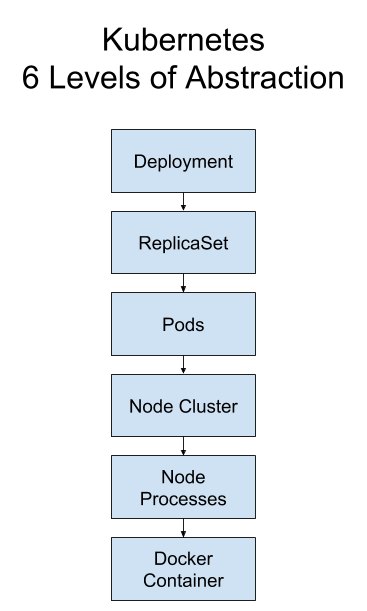
从高层抽象到底层可以描述为:
Deployment 创建和管理ReplicaSet; ReplicaSet创建和管理Pod; pod运行在某一个node上,node上具有一个容器运行时环境,可以运行容器化的应用。
如果对于工作节点的抽象进行细化:
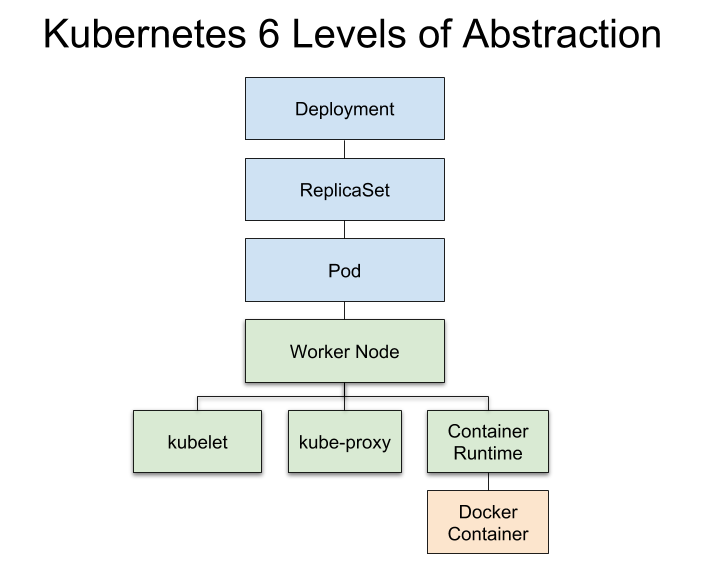
底色为蓝色的层属于高层抽象,底色为绿色的层属于低层抽象
2.2 Deployment
Deployment 为 Pod 以及 ReplicaSet 提供了一个声明式 (declarative )的定义,用以代替原来的 ReplicaSetController, 方便管理应用。对于一个无状态并且连续运行的应用,Deployment 是最好的选择,可以提供不停机运行以及更新(No downtime),同时具有 Pods 重启的策略。典型的用例:
使用Deployment来创建 ReplicaSet, ReplicaSet 后台创建 Pods, 检查启动状态
更新 Deployment 的
spec.template.spec字段可以更新 Pods 的状态会创建一个新的 ReplicaSet, Deployment 会按照控制的速率从旧的 ReplicaSet 移动到新的 ReplicaSet如果当前状态不稳定,回滚到之前的 Deployment revision。每次回滚都会更新 Deployment 的 revision。
扩容 Deployment 以满足更高的负载。
暂停 Deployment 来应用 PodTemplateSpec 的多个修复,然后恢复上线。
根据 Deployment 的状态判断上线是否 hang 住了。
清除旧的不必要的 ReplicaSet。
2.3 ReplicaSet
由 Deployment 创建的 ReplicaSet 保证应用以期望的副本数运行,ReplicaSets 会基于设定创建并伸缩 Pods,如果有Pod异常退出,会创建新的 Pod替代,产生异常的Pod也会被回收, ReplicaSet 的典型应用场景包括典型应用场景包括确保健康 Pod 的数量、弹性伸缩、滚动升级以及应用多版本发布跟踪等。
旧版本的 ReplicationController 也具有相同的功能,二者本质没有差别,但是 ReplicaSet 支持集合式的selector (RC仅支持等式)
虽然也 ReplicaSet 可以独立使用,但建议使用 Deployment 来自动管理 ReplicaSet,这样就无需担心跟其他机制的不兼容问题(比如 ReplicaSet 不支持 rolling-update 但 Deployment 支持),并且还支持版本记录、回滚、暂停升级等高级特性。
2.4 Pod
Pod 是k8s最基本的构造单元,一个 Pod 包含了一个至多个容器,是一组紧密关联的容器集合。他们共享 IPC, Network,UTS namespace, 是基本调度单位。由于支持多个容器共享资源,可以高效简单的组合完成任务。
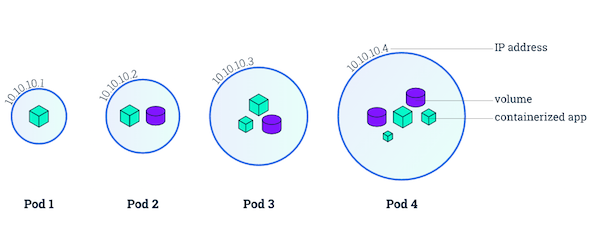
Pod 的特征:
包含多个共享 IPC、Network 和 UTC namespace 的容器,可直接通过 localhost 通信
所有 Pod 内容器都可以访问共享的 Volume,可以访问共享数据
无容错性:直接创建的 Pod 一旦被调度后就跟 Node 绑定,即使 Node 挂掉也不会被重新调度(而是被自动删除),因此推荐使用 Deployment、Daemonset 等控制器来容错
优雅终止:Pod 删除的时候先给其内的进程发送 SIGTERM,等待一段时间(grace period)后才强制停止依然还在运行的进程
特权容器(通过 SecurityContext 配置)具有改变系统配置的权限(在网络插件中大量应用)

2.5 Node
Node 是容器真正运行的主机,可以是物理机或者虚拟机,在一个 k8s 集群中 Node 有两种身份 Master、Worker;不像其他资源,node本身不是 k8s 创建的,k8s 知识管理 node 上的资源,虽然可以通过 manifest 创建一个Node对象,但是k8s也只是去检查是否存在该 node,如果检查失败也不会调度 Pod 上去。

Cluster master
master 结点维护整个集群的状态,并且进行资源的调度以及管理,基本的组件包括:
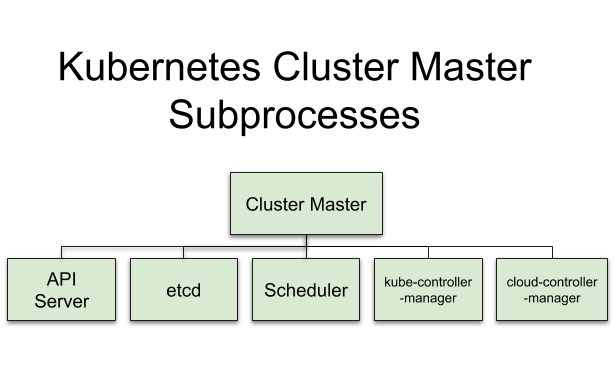
kube-apiserver: 暴露 k8s API,作为k8s控制的前端入口;类比中转站
etcd: 分布式 key-value 存储工具,用于保存集群数据
kube-scheduler: 为新创建的 Pod 分配 node
kube-controller-manager: 运行controllers,处理集群的一些后台任务
cloud-controller-manager: 与云服务提供商交互的接口
Worker node
work 节点至少包含以下组件:
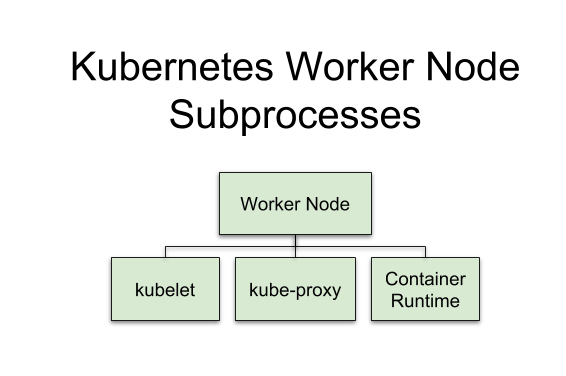
kubelet: 负责worker node的所有事情,与master节点的ApiServer交互,作为工作节点的“大脑”
kube-proxy: 将网络连接Route到对应的Pods上,同时负责对于属于同一个service的pods的负载均衡;类比“交通警察”
Container runtime:管理镜像运行容器,容器运行时环境
3. ReplicaSet、StatefulSet and DaemonSet
前文提到的 ReplicaSet 用于无状态服务的 Pod 的管理,那么对于有状态服务呢?或者需要在每一个节点全都步数的服务呢?这个时候就需要用到 StatefulSet 以及 DaemonSet。
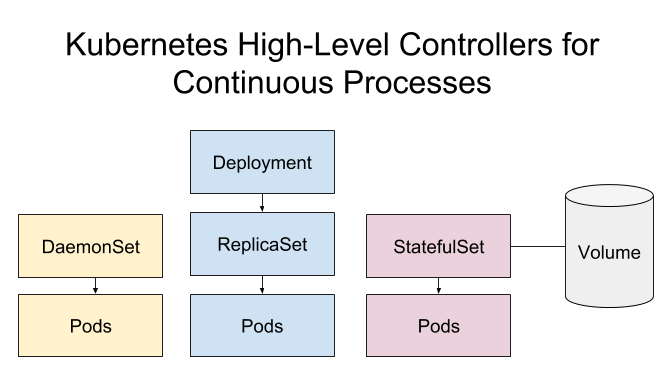
3.1 StatefulSet
StatefulSet 用以解决有状态服务的问题,应用场景包括:
稳定的持久化存储,即 Pod 重新调度后还是能访问到相同的持久化数据,基于 PVC 来实现
稳定的网络标志,即 Pod 重新调度后其 PodName 和 HostName 不变,基于 Headless Service(即没有 Cluster IP 的 Service)来实现
有序部署,有序扩展,即 Pod 是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依序进行(即从 0 到 N-1,在下一个 Pod 运行之前所有之前的 Pod 必须都是 Running 和 Ready 状态),基于 init containers 来实现
有序收缩,有序删除(即从 N-1 到 0)
与 ReplicaSet 类似, StatefulSet 基于container spec部署以及伸缩一组 Pods;与 Deployment 不同,StatefulSet 的pods是不可以互换的,因为每一个pods都是有状态的,所以在由 Controller 调度维护的过程中,每一个 Pod都有一个唯一的持久标识符。适用于持久化的应用,例如数据库。
StatefulSet pods 的数据通过 volume 进行持久化。
3.2 DaemonSet
DaemonSer 保证在每一个 Node 上都运行一个容器副本,通常用于部署集群的日志、监控等应用,典型场景:
日志收集,比如 fluentd,logstash 等
系统监控,比如 Prometheus Node Exporter,collectd,New Relic agent,Ganglia gmond 等
系统程序,比如 kube-proxy, kube-dns, glusterd, ceph 等
StatefulSet 以及 DaemonSet 不受 Deployment 的管理以及控制,虽然他们与 ReplicaSet 处于同一级别的抽象,但是在当前版本的APi中没有对它更高级别的抽象
4. Jobs and CronJobs
k8s 的 Jobs 以及 CronJobs 分别用于执行一次性任务以及定时任务
4.1 Jobs
Jobs 负责批量处理短暂的一次性任务(short lived one-off tasks),可以根据需要处理的批处理任务创建一定数量的 Pods,并且保证其成功执行。与 ReplicaSet 不同,一旦一个任务成功执行,该容器就不会重启,仅运行一次。
Jobs 可以根据声明的状态分为以下几类:
Job 类型
使用示例
行为
completions
parallelism
一次性 Job
数据库迁移
创建一个Pod直到运行成功
1
1
固定结束次数的Job
处理工作队列中的Job
创建一个Pod运行,直到completions个成功
2+
1
固定结束次数的并行Job
多个Pod同时处理工作队列
创建多个Pods运行,直到completions个成功
2+
2+
并行Job
多个Pod同时处理工作队列
创建多个Pods,直到有一个运行成功
1
2+
Job Controller
Job Controller 负责根据 Job Spec 创建 Pod,并持续监控 Pod 的状态,直至其成功结束。如果失败,则根据 restartPolicy(只支持 OnFailure 和 Never,不支持 Always)决定是否创建新的 Pod 再次重试任务。
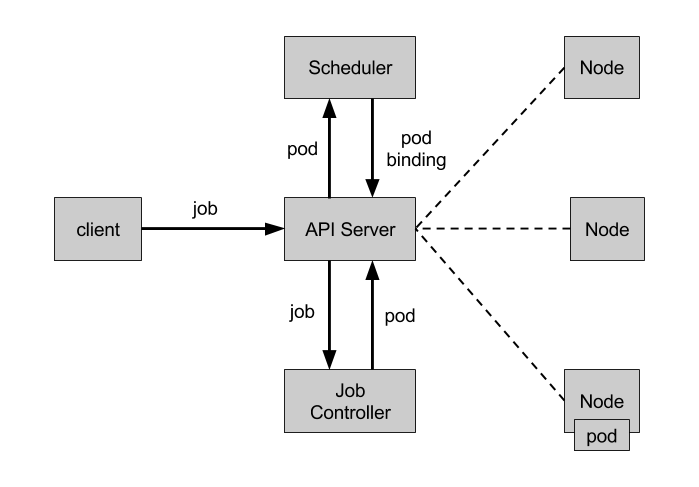
4.2 CronJob
用于运行定时任务,类似于 crontab,可以在指定的时间周期内运行任务。
cronJob spec:
.spec.schedule指定任务运行周期,格式同 Cron.spec.jobTemplate指定需要运行的任务,格式同 Job.spec.startingDeadlineSeconds指定任务开始的截止期限.spec.concurrencyPolicy指定任务的并发策略,支持 Allow、Forbid 和 Replace 三个选项
5. Service and service account
在 k8s 中 pods 是一个“凡人”,它们诞生后死亡是无法”复活“的。如果使用 Deployment 来管理Pods,会动态的创建以及销毁 Pods。 对于每一个 Pods,都有自己的IP地址,这就导致了一个问题,如果多个pods提供相同的功能,该如何确定使用该服务时所连接的ip呢?这就产生了服务的概念。
5.1 Service
Service 是对一组提供相同功能的 Pods 的抽象,并为他们提供统一的入口,定义了一个Pods的逻辑集合以及访问策略(这种方式也被称为微服务)。借助 Service,应用可以方便的实现服务发现与负载均衡,并实现应用的零宕机升级。Service 通过标签来选取服务后端,一般配合 Replication Controller 或者 Deployment 来保证后端容器的正常运行。这些匹配标签的 Pod IP 和端口列表组成 endpoints,由 kube-proxy 负责将服务 IP 负载均衡到这些 endpoints 上。
Service 有以下类型:
ClusterIP:默认类型,自动分配一个仅 cluster 内部可以访问的虚拟 IPNodePort:在 ClusterIP 基础上为 Service 在每台机器上绑定一个端口,这样就可以通过 :NodePort 来访问该服务。如果 kube-proxy 设置了 --nodeport-addresses=10.240.0.0/16(v1.10 支持),那么仅该 NodePort 仅对设置在范围内的 IP 有效。LoadBalancer:在 NodePort 的基础上,借助 cloud provider 创建一个外部的负载均衡器,并将请求转发到<NodeIP>:NodePortExternalName:将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定)。需要 kube-dns 版本在 1.7 以上。
service详解见后续章节 或者 blog[https://medium.com/@SandeepDinesh]
6. Volumes, PersistentVolumes and PersistentVolumeClaims
6.1 Volumes
容器默认的数据是非持久的,容器消亡后,数据也被删除,所以Docker提供了 Volume 进行持久化,对应 k8s 提供了更为强大的 Volume机制以及丰富的插件,解决了容器持久化以及容器共享数据的问题。与docker不同,k8s的 volume 的生命周期与 Pod 绑定。
容器挂掉后,kubelet 再次重启容器,volume依然存在
而 Pod 删除时,Volume 才会清理。数据是否丢失取决于具体的 Volume 类型,比如 emptyDir 的数据会丢失,而 PV 的数据则不会丢
一个Pod的Volume可以被pod内所有的容器访问,对于独立的volume必须单独挂载。k8s Volume 可以提供磁盘存储、内存存储、以及云存储,一个Pod可以同时运用这些方式。
6.2 PersistentVolume (PV)and PersistentVolumeCliam (PVC)
为了使得 Pods 创建时远离基础设施, k8s 使用PV, PVC 将volume的生命周期与 Pods 解耦。有了PV 以及PVC之后,进行数据持久化时,只需要关注两个点:
一个 PersistentVolume 已经被加入到集群中,或者动态加入
对于一个 Pod 来说,如果需要PV资源,只需要创建一个 PersistentVolumeCliams manifest,指定所需要的存储类型以及容量, k8s 会分配所需的资源
使用这种抽象, Pod 不需要和硬件资源打交道,实际上, Pod 甚至只需要了解 PVC, 不需要了解PV
7. 小结
本章对于 k8s 的基本概念以及各级抽象进行了概述,对于一个 Deployment 有6级抽象:
Deployment: 管理 ReplicaSets. 适用于持久化的无状态应用 (e.g. HTTP servers).
ReplicaSet: 创建以及管理 Pods.
Pod: K8s 调度的基本单元
Node Cluster: Worker Nodes + Cluster Master.
- Worker Nodes: Pods 实际运行的机器
- Cluster Master: 管理整个集群
Node Processes
Master node 组件:
- API server: 中转站
- etcd: 集群信息.
- scheduler: 分配者
- kube-controller-manager: 管理者
- cloud-controller-manager: 云接口
Worker node 组件:
- kubelet: 工作节点大脑
- kube-proxy: 交警
- container-runtime: Docker.
Docker Container: 管理镜像,运行容器
还有7个高水平的 k8s 资源抽象:
StatefulSet: 类似 ReplicaSet, 处理有状态应用
DaemonSet: 每个节点都执行的进程 eg: monitor
Job: 短时任务
CronJob: 定时任务
Service: Pods 的统一入口
Volume: 存储数据
PersistentVolume, PersistentVolumeClaim: 定义与分配存储资源
Reference:
Last updated